- R에서 데이터를 보관, 정리, 분석하는 데 핵심적인 역할을 했던 것이 Dataframe인데, Python의 Pandas 라이브러리가 이것을 그대로 가져왔습니다.
- Pandas는 numpy를 이용해서 만들어졌습니다. numpy에 추가로 편한 기능들이 들어간 것입니다. 특히 pandas는 표 형식의 data를 다루는데 매우 유용합니다.

- 대부분의 dataset은 2차원이고, 이러한 2차원 형태의 데이터를 다루기 위한 자료형이 Pandas의 DataFrame입니다. 이는 일반적인 2차원 numpy array에 부가적인 기능들이 추가된 것입니다.
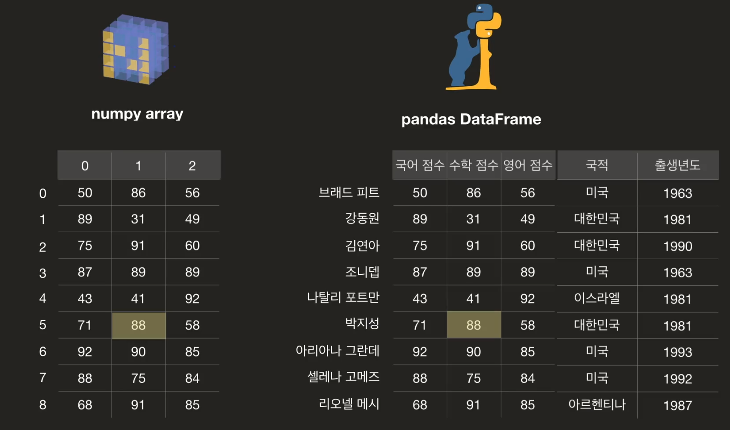
- numpy array는 숫자 인덱스로 값을 찾아냈다면, pandas DataFrame에서는 정해준 이름으로 값을 찾을 수 있습니다.
또한, numpy array는 숫자를 담고, pandas DataFrame은 다양한 자료형을 담을 수 있습니다.
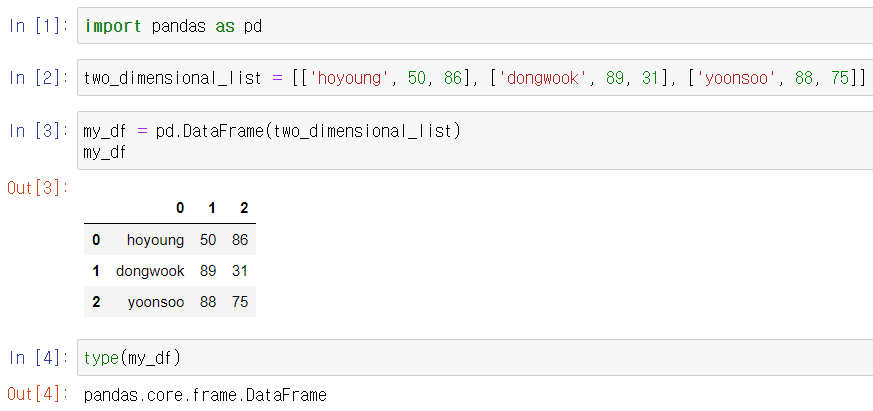
- pandas DataFrame은 column이랑 row에 이름을 붙여줄 수 있는데, 이름을 따로 안 붙여주면, 0,1,2,... 순서로 숫자가 부여됩니다.
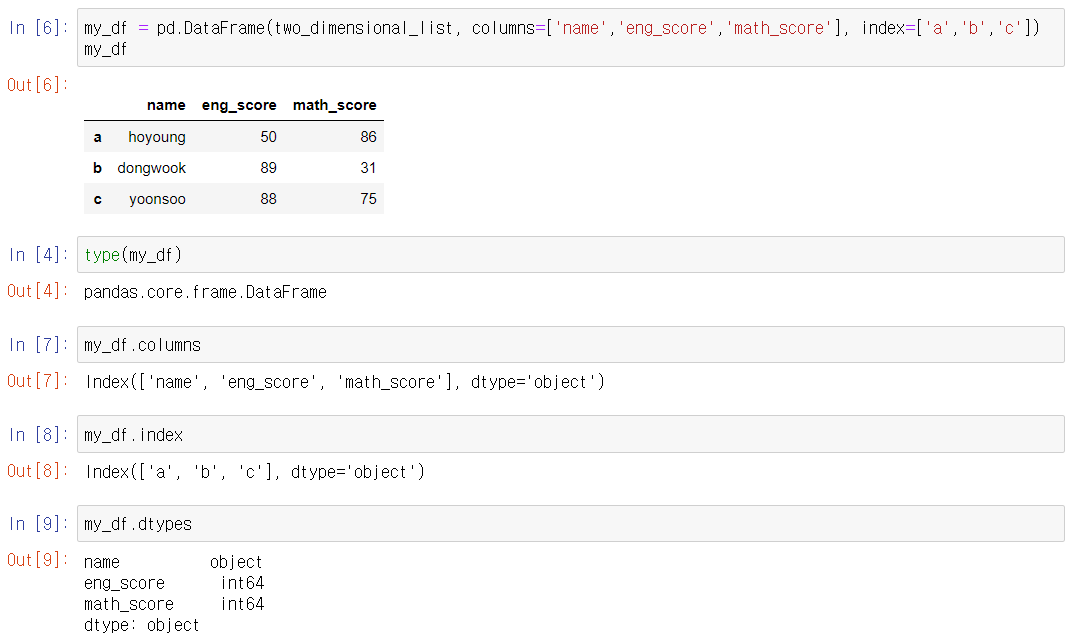
- pandas dataframe에서 object는 문자열을 나타냅니다. 한 dataframe내에서 다양한 자료형을 담을 수 있지만, 같은 column끼리는 같은 자료형이어야 합니다.
<dataframe을 만드는 다양한 방법>
2차원 리스트나 2차원 numpy array로 DataFrame을 만들 수 있습니다. 심지어 pandas Series를 담고 있는 리스트로도 DataFrame을 만들 수 있습니다.
import numpy as np
import pandas as pd
two_dimensional_list = [['dongwook', 50, 86], ['sineui', 89, 31], ['ikjoong', 68, 91], ['yoonsoo', 88, 75]]
two_dimensional_array = np.array(two_dimensional_list)
list_of_series = [
pd.Series(['dongwook', 50, 86]),
pd.Series(['sineui', 89, 31]),
pd.Series(['ikjoong', 68, 91]),
pd.Series(['yoonsoo', 88, 75])
]
# 아래 셋은 모두 동일합니다
df1 = pd.DataFrame(two_dimensional_list)
df2 = pd.DataFrame(two_dimensional_array)
df3 = pd.DataFrame(list_of_series)
0 1 2
0 dongwook 50 86
1 sineui 89 31
2 ikjoong 68 91
3 yoonsoo 88 75
파이썬 사전(dictionary)으로도 DataFrame을 만들 수 있습니다.
사전의 key로는 column 이름을 쓰고, 그 column에 해당하는 리스트, numpy array, 혹은 pandas Series를 사전의 value로 넣어주면 됩니다.
import numpy as np
import pandas as pd
names = ['dongwook', 'sineui', 'ikjoong', 'yoonsoo']
english_scores = [50, 89, 68, 88]
math_scores = [86, 31, 91, 75]
dict1 = {
'name': names,
'english_score': english_scores,
'math_score': math_scores
}
dict2 = {
'name': np.array(names),
'english_score': np.array(english_scores),
'math_score': np.array(math_scores)
}
dict3 = {
'name': pd.Series(names),
'english_score': pd.Series(english_scores),
'math_score': pd.Series(math_scores)
}
# 아래 셋은 모두 동일합니다
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
df3 = pd.DataFrame(dict3)
name english_score math_score
0 dongwook 50 86
1 sineui 89 31
2 ikjoong 68 91
3 yoonsoo 88 75
리스트가 담긴 사전이 아니라, 사전이 담긴 리스트로도 DataFrame을 만들 수 있습니다.
import numpy as np
import pandas as pd
my_list = [
{'name': 'dongwook', 'english_score': 50, 'math_score': 86},
{'name': 'sineui', 'english_score': 89, 'math_score': 31},
{'name': 'ikjoong', 'english_score': 68, 'math_score': 91},
{'name': 'yoonsoo', 'english_score': 88, 'math_score': 75}
]
df = pd.DataFrame(my_list)
english_score math_score name
0 50 86 dongwook
1 89 31 sineui
2 68 91 ikjoong
3 88 75 yoonsoo
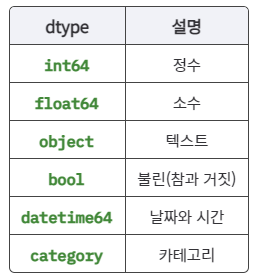
- pandas에 담을 수 있는 dtype(데이터 타입)은 다음과 같습니다.
- CSV는 Comma-Separated Values의 줄임말로, 쉼표로 분리된 파일형식을 나타냅니다.
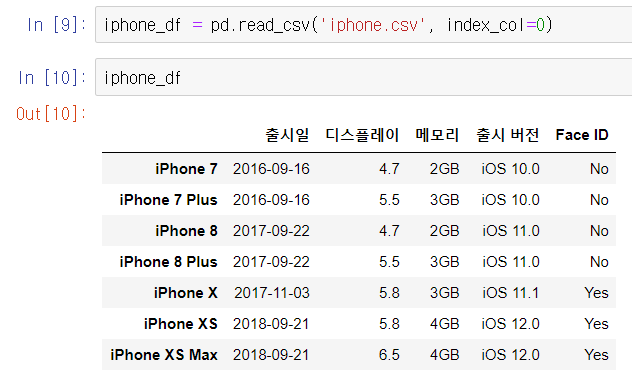
,출시일,디스플레이,메모리,출시 버전,Face ID
iPhone 7,2016-09-16,4.7,2GB,iOS 10.0,No
iPhone 7 Plus,2016-09-16,5.5,3GB,iOS 10.0,No
iPhone 8,2017-09-22,4.7,2GB,iOS 11.0,No
iPhone 8 Plus,2017-09-22,5.5,3GB,iOS 11.0,No
iPhone X,2017-11-03,5.8,3GB,iOS 11.1,Yes
iPhone XS,2018-09-21,5.8,4GB,iOS 12.0,Yes
iPhone XS Max,2018-09-21,6.5,4GB,iOS 12.0,Yes

- csv파일의 header가 없는 경우, read_csv에 parameter header로 None을 넘겨줘야 합니다.
iphone_df = pd.read_csv('iphone.csv', header=None)
- index_col = 0을 하면, 0번째 column을 index(row) 이름으로 설정합니다.
- 몇 번째 Column인지 명확하지 않을 때는 숫자 0 대신 index_col='Draw Date' 라고 이름을 직접 적용해도 됩니다.
df = pd.read_csv('data/mega_millions.csv', index_col='Draw Date')'인공지능(AI) > 코드잇_데이터 사이언스 입문' 카테고리의 다른 글
| [DataFrame 다루기] 데이터 변형하기 (0) | 2021.05.13 |
|---|---|
| [DataFrame 다루기] DataFrame 인덱싱 (0) | 2021.05.13 |
| [데이터 사이언스 시작하기] Numpy (0) | 2021.04.29 |
| [데이터 사이언스 시작하기] Jupyter Notebook (0) | 2021.04.25 |
| [데이터 사이언스 시작하기] 데이터 사이언스란? (0) | 2021.04.25 |


